
開發能夠像人類一樣推理的靈活機器學習模型的關鍵可能不是向它們提供海量訓練資料。相反,一項新的研究表明,答案可能在於如何訓練它們。這些發現可能是朝著更好、更少出錯的人工智慧模型邁出的重要一步,並可能有助於闡明人工智慧系統——以及人類——如何學習的秘密。
人類是混音大師。當人們理解一組成分(如食物配料)之間的關係時,我們可以將它們組合成各種美味的食譜。對於語言,我們可以理解以前從未遇到過的句子,並撰寫複雜、原創的回應,因為我們掌握了詞語的潛在含義和語法規則。在技術術語中,這兩個例子都是“組合性”或“系統泛化”的證據——通常被視為人類認知的關鍵原則。“我認為這是智慧最重要的定義,”約翰·霍普金斯大學的認知科學家保羅·斯莫倫斯基說。“你可以從瞭解部分到處理整體。”
真正的組合性可能是人類思維的核心,但機器學習開發者幾十年來一直在努力證明人工智慧系統能夠實現它。已故哲學家和認知科學家傑裡·福多和芝諾·皮利辛提出的一個35年前的論點認為,對於標準神經網路來說,這一原則可能遙不可及。今天的生成式人工智慧模型可以模仿組合性,對書面提示產生類似人類的回應。然而,即使是最先進的模型,包括 OpenAI 的 GPT-3 和 GPT-4,仍然達不到這一能力的一些基準。例如,如果你向 ChatGPT 提問,它最初可能會提供正確的答案。但是,如果你繼續向它傳送後續查詢,它可能會無法保持主題,或者開始自相矛盾。這表明,儘管這些模型可以從它們的訓練資料中回 regurgitate 資訊,但它們並沒有真正掌握它們產生的句子背後的含義和意圖。
支援科學新聞報道
如果您喜歡這篇文章,請考慮透過訂閱來支援我們屢獲殊榮的新聞報道。透過購買訂閱,您正在幫助確保有關塑造我們今天世界的發現和想法的有影響力的故事的未來。 訂閱。透過購買訂閱,您正在幫助確保有關塑造我們今天世界的發現和想法的有影響力的故事的未來。
但是,根據週三發表在《自然》雜誌上的一項研究,一種專注於塑造神經網路學習方式的新型訓練協議可以提高人工智慧模型像人類一樣解釋資訊的能力。研究結果表明,某種人工智慧教育方法可能建立組合式機器學習模型,使其至少在某些情況下能夠像人類一樣進行泛化。
“這項研究取得了重要的突破,”未參與該研究的斯莫倫斯基說。“它完成了一些我們一直想完成但以前沒有成功的事情。”
為了訓練一個似乎能夠重組元件並理解新穎、複雜表達方式含義的系統,研究人員不必從頭開始構建人工智慧。“我們不需要從根本上改變架構,”該研究的主要作者、紐約大學的計算認知科學家布倫丹·萊克說。“我們只需要給它練習。”研究人員從一個標準的 Transformer 模型開始——該模型是支援 ChatGPT 和 Google 的 Bard 的那種人工智慧支架,但缺乏任何先前的文字訓練。他們讓這個基本的神經網路透過一套專門設計的任務,旨在教程式如何理解一種虛構的語言。
該語言由無意義的詞語組成(如“dax”、“lug”、“kiki”、“fep”和“blicket”),這些詞語“翻譯”成一組彩色點。其中一些虛構的詞語是符號術語,直接表示某種顏色的點,而另一些則表示改變點輸出順序或數量的函式。例如,dax 代表一個簡單的紅點,但 fep 是一個函式,當與 dax 或任何其他符號詞配對時,會將其對應的點輸出乘以三。所以“dax fep”會翻譯成三個紅點。然而,人工智慧訓練不包括任何這些資訊:研究人員只是向模型提供了一些無意義的句子示例,並附帶相應的點集。
從那裡,研究作者提示模型產生其自己的一系列點來響應新的短語,並根據人工智慧是否正確遵循了該語言的隱含規則對其進行評分。很快,神經網路就能夠連貫地響應,遵循無意義語言的邏輯,即使在引入新的詞語配置時也是如此。這表明它可以“理解”該虛構語言的虛構規則,並將它們應用於它沒有接受過訓練的短語。
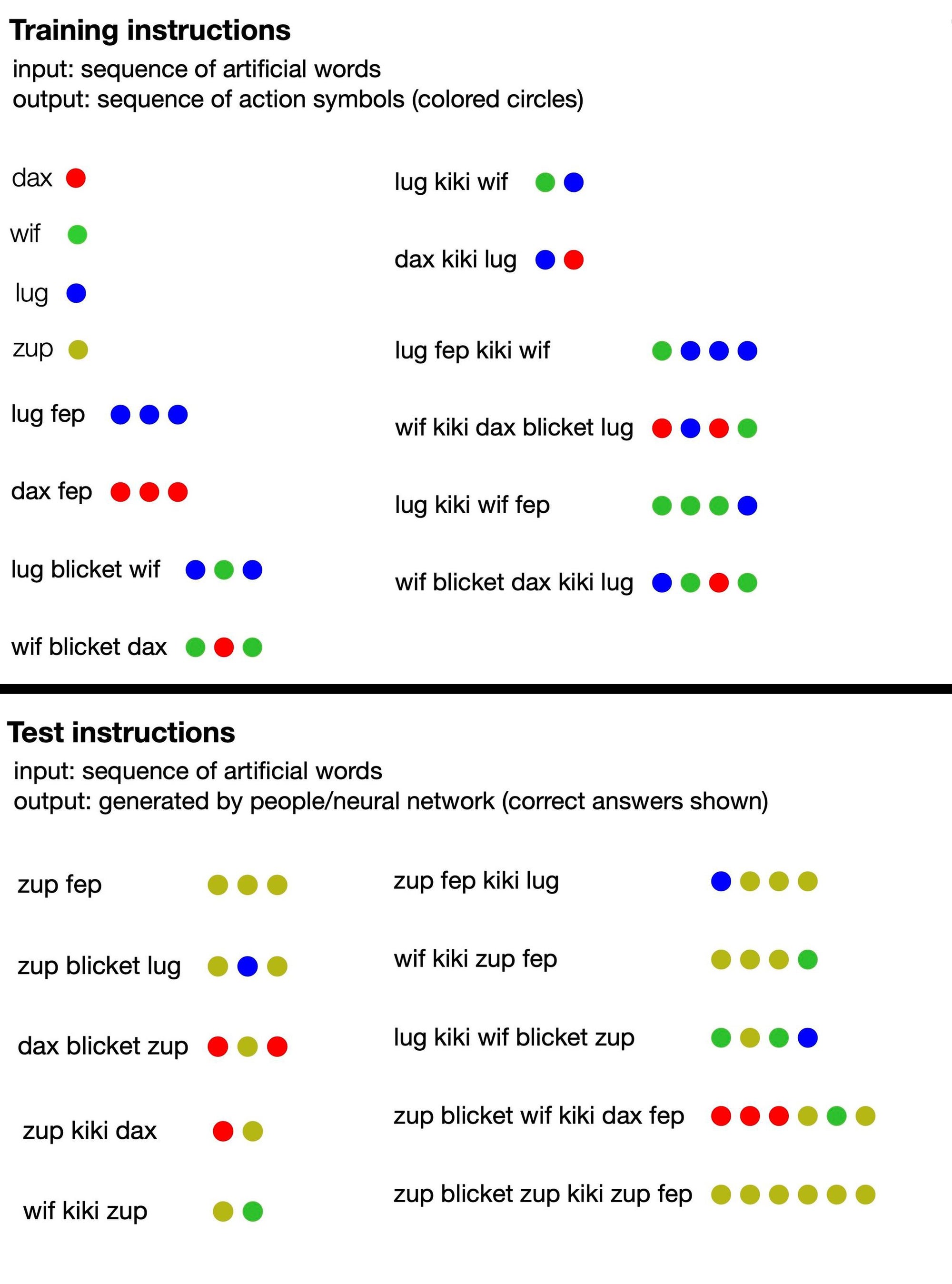
來自計算認知科學家 Brenden Lake 及其同事關於一項新的Nature研究的新聞稿中的一張圖表顯示了人類參與者和人工智慧模型都收到的訓練材料(頂部),以及他們接受測試的提示型別和正確答案(底部)。 鳴謝:Brenden Lake
此外,研究人員測試了他們訓練有素的人工智慧模型對虛構語言的理解,並與 25 名人類參與者進行了比較。他們發現,在最佳狀態下,他們最佳化的神經網路的響應準確率達到 100%,而人類答案的正確率約為 81%。(當團隊向 GPT-4 提供語言的訓練提示,然後向其提出測試問題時,大型語言模型的準確率僅為 58%。) 鑑於額外的訓練,研究人員的標準 Transformer 模型開始非常逼真地模仿人類推理,以至於它也犯了同樣的錯誤:例如,人類參與者經常犯錯,他們假設特定詞語和點之間存在一對一的關係,即使許多短語不遵循該模式。當模型被提供這種行為的例子時,它很快開始複製它,並且犯錯的頻率與人類相同。
考慮到模型的小尺寸,模型的效能尤其引人注目。“這不是一個在整個網際網路上訓練的大型語言模型;這是一個相對較小的 Transformer 模型,專門針對這些任務進行訓練,”未參與這項新研究的麻省理工學院的計算機科學家 Armando Solar-Lezama 說。“有趣的是,儘管如此,它還是能夠表現出這些型別的泛化能力。” 這一發現暗示,與其僅僅向機器學習模型中塞入越來越多的訓練資料,不如採取一種互補策略,為人工智慧演算法提供相當於專注的語言學或代數課程。
Solar-Lezama 說,這種訓練方法理論上可以為更好的人工智慧提供另一條途徑。“一旦你向模型提供了整個網際網路,就沒有第二個網際網路可以提供給它以進一步改進。因此,我認為迫使模型更好地推理的策略,即使在合成任務中,也可能對未來產生影響,”他說——但同時警告說,擴充套件新的訓練協議可能存在挑戰。同時,Solar-Lezama 認為,對較小模型的研究有助於我們更好地理解神經網路的“黑匣子”,並可能闡明更大的人工智慧系統的所謂的新興能力。
斯莫倫斯基補充說,這項研究以及未來類似的工作,也可能提高人類對自身思維的理解。這可能有助於我們設計系統,最大限度地減少我們人類容易出錯的傾向。
然而,目前,這些好處仍然是假設性的——並且存在一些很大的侷限性。“儘管他們的演算法取得了成功,但它並沒有解決提出的所有挑戰,”未參與該研究的卡內基梅隆大學的計算機科學家 Ruslan Salakhutdinov 說。“它不會自動處理未經練習的泛化形式。” 換句話說,訓練協議幫助模型擅長於一種型別的任務:學習虛構語言中的模式。但是,如果給定一個全新的任務,它就無法應用相同的技能。這在基準測試中很明顯,模型無法處理更長的序列,也無法理解以前未引入的“詞語”。
至關重要的是,每位《大眾科學》採訪的專家都指出,能夠進行有限泛化的神經網路與通用人工智慧的聖盃截然不同,後者是指計算機模型在大多數任務中超越人類能力。你可以說,“這是朝著那個方向邁出的非常非常非常小的一步,”Solar-Lezama 說。“但我們談論的不是人工智慧自行獲得能力。”
從與人工智慧聊天機器人的有限互動(可以呈現出超強能力的錯覺)以及大量流傳的炒作來看,許多人可能對神經網路的能力抱有誇大的想法。“有些人可能會感到驚訝,像 GPT-4 這樣的系統真的很難開箱即用地完成這些型別的語言泛化任務,”Solar-Lezama 說。不過,這項新研究的發現雖然令人興奮,但可能會無意中起到現實檢驗的作用。“真正重要的是要跟蹤這些系統能夠做什麼,”他說,“以及它們不能做什麼。”