
考慮一下安迪,他擔心在2020年感染新冠病毒。由於無法閱讀所有關於新冠病毒的文章,他依靠信任的朋友提供建議。當一位朋友在Facebook上評論說對疫情的恐懼被誇大了時,安迪起初不以為然。但隨後,他工作的酒店關門了,他的工作岌岌可危,安迪開始懷疑病毒的威脅到底有多嚴重。畢竟,他認識的人中沒有人因此喪生。一位同事釋出了一篇文章,稱新冠“恐慌”是由大型製藥公司與腐敗政客勾結制造的,這與安迪對政府的不信任不謀而合。他的網路搜尋很快將他帶到一些文章,聲稱新冠病毒並不比流感更嚴重。安迪加入了一個由失業或擔心失業的人組成的線上群組,很快發現自己像他們中的許多人一樣問道:“什麼疫情?” 當他得知幾位新朋友計劃參加一次要求結束封鎖的集會時,他決定加入他們。包括他在內,幾乎沒有人在這場大規模抗議活動中戴口罩。當他的姐姐詢問集會時,安迪分享了他現在已成為他身份一部分的信念:新冠病毒是一場騙局。
這個例子說明了一個認知偏差的雷區。我們更喜歡來自我們信任的人、我們群體內部的資訊。我們關注風險資訊,也更可能分享風險資訊——對安迪來說,是失去工作的風險。我們會搜尋並記住與我們已知和理解的事物相符的資訊。這些偏差是我們進化過去的產物,在數萬年裡,它們對我們很有幫助。那些行為符合這些偏差的人——例如,遠離有人說有毒蛇的雜草叢生的池塘邊——比那些不這樣做的人更有可能生存下來。
然而,現代技術正在以有害的方式放大這些偏差。搜尋引擎將安迪導向加劇他懷疑的網站,社交媒體將他與志同道合的人聯絡起來,加劇了他的恐懼。更糟糕的是,機器人——模仿人類的自動化社交媒體賬戶——使誤入歧途或懷有惡意的行為者能夠利用他的弱點。
關於支援科學新聞
如果您喜歡這篇文章,請考慮支援我們屢獲殊榮的新聞事業,方式是 訂閱。透過購買訂閱,您正在幫助確保有關當今塑造我們世界的發現和想法的具有影響力的故事的未來。
線上資訊的激增加劇了這個問題。檢視和製作部落格、影片、推文和其他稱為“迷因”的資訊單元變得如此廉價和容易,以至於資訊市場充斥著資訊。由於無法處理所有這些材料,我們讓認知偏差決定我們應該關注什麼。這些心理捷徑在有害的程度上影響著我們搜尋、理解、記住和重複哪些資訊。
理解這些認知漏洞以及演算法如何使用或操縱它們已變得迫在眉睫。在英國華威大學和印第安納大學布盧明頓分校的社交媒體觀察站 (OSoMe,發音為“awesome”),我們的團隊正在使用認知實驗、模擬、資料探勘和人工智慧來理解社交媒體使用者的認知漏洞。在華威大學進行的關於資訊進化的心理學研究的見解為印第安納大學開發的計算機模型提供了資訊,反之亦然。我們還在開發分析和機器學習輔助工具,以對抗社交媒體操縱。記者、公民社會組織和個人已經在使用其中一些工具來檢測虛假行為者,繪製虛假敘事的傳播圖,並培養新聞素養。
資訊過載
資訊的過剩引發了對人們注意力的激烈競爭。正如諾貝爾經濟學獎得主和心理學家赫伯特·A·西蒙所指出的,“資訊消耗的東西顯而易見:它消耗了接收者的注意力。” 所謂注意力經濟的首要後果之一是高質量資訊的流失。OSoMe團隊透過一組簡單的模擬演示了這一結果。它將社交媒體使用者(如安迪)稱為代理,表示為線上熟人網路中的節點。在模擬的每個時間步,代理可以建立迷因,也可以轉發在新聞提要中看到的迷因。為了模擬有限的注意力,代理只能檢視新聞提要頂部附近的有限數量的專案。
莉蓮·翁(現就職於OpenAI)和OSoMe的研究人員發現,在多次時間步執行此模擬後,隨著代理的注意力變得越來越有限,迷因的傳播開始反映實際社交媒體的冪律分佈:迷因被分享給定次數的機率大約是該次數的倒冪。例如,迷因被分享三次的可能性大約是其被分享一次的九分之一。
迷因的這種贏家通吃的流行模式(大多數迷因幾乎無人注意,而少數迷因卻廣泛傳播)無法用其中一些迷因更吸引人或在某種程度上更有價值來解釋:這個模擬世界中的迷因沒有內在質量。病毒式傳播純粹是由注意力有限的代理社交網路中資訊擴散的統計結果造成的。即使代理優先分享高質量的迷因,當時在OSoMe的研究員邱曉燕也觀察到,在分享最多的迷因的整體質量方面幾乎沒有改善。我們的模型揭示,即使我們想看到和分享高質量的資訊,我們無法檢視新聞提要中的所有內容也必然會導致我們分享部分或完全不真實的內容。
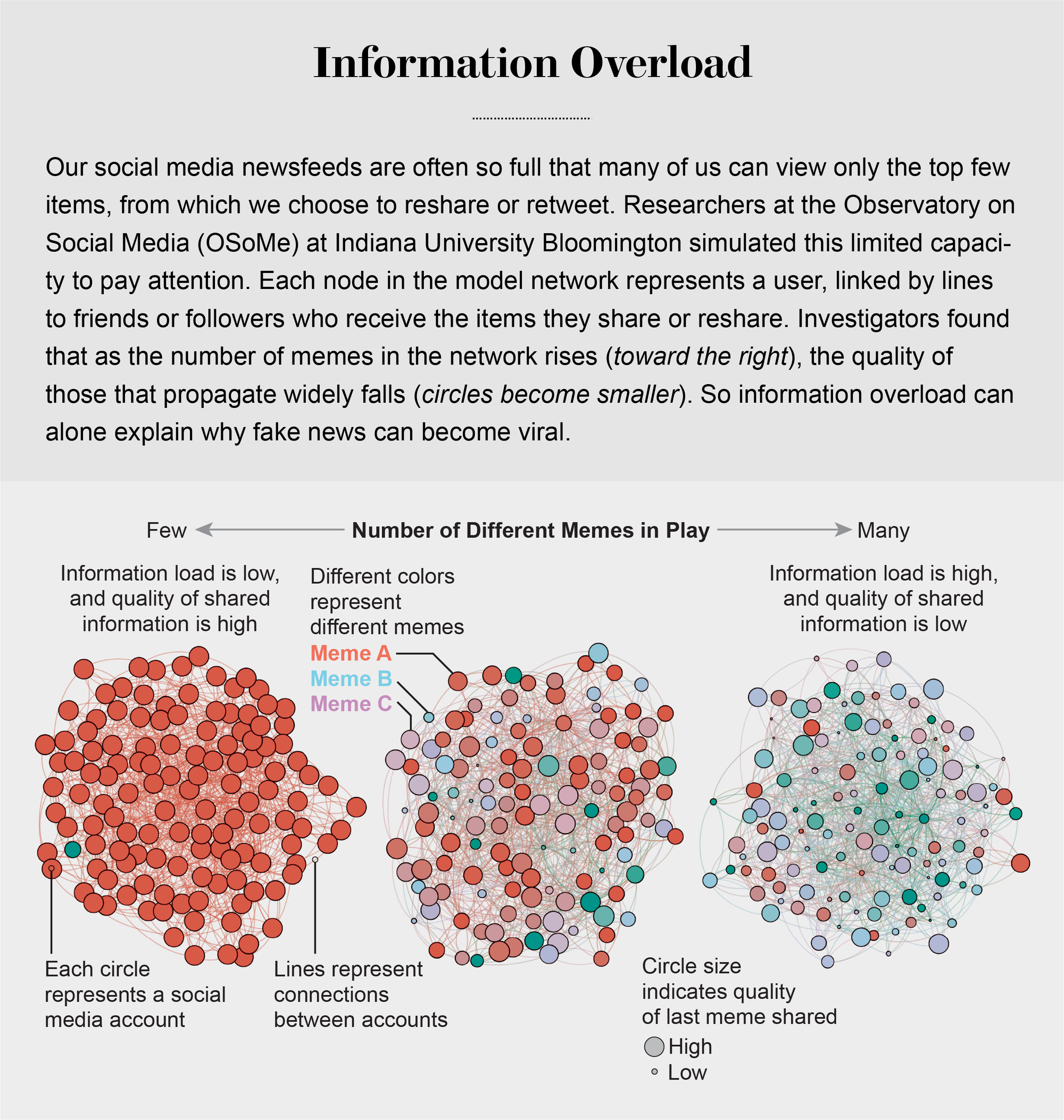
來源:“個人注意力有限和低質量資訊的線上病毒式傳播”,作者:邱曉燕等,發表於《自然人類行為》,第1卷,2017年6月
認知偏差大大加劇了這個問題。在1932年進行的一系列開創性研究中,心理學家弗雷德里克·巴特利特給志願者講述了一個關於年輕人的美洲原住民傳說,這個年輕人聽到戰爭的呼喊聲,追逐著它們,進入了一場夢幻般的戰鬥,最終導致了他的真正死亡。巴特利特要求這些非美洲原住民志願者在越來越長的時間間隔(從幾分鐘到幾年後)回憶起這個相當令人困惑的故事。他發現,隨著時間的推移,記憶者傾向於扭曲故事中不熟悉的文化部分,使它們要麼被記憶遺忘,要麼轉化為更熟悉的事物。我們現在知道,我們的大腦一直都在這樣做:它們調整我們對新資訊的理解,使其與我們已知的資訊相符。這種所謂的證實偏差的一個結果是,人們經常尋找、回憶和理解最能證實他們已經相信的資訊。
這種傾向極其難以糾正。實驗一致表明,即使人們遇到包含來自不同視角的觀點的平衡資訊,他們也傾向於為自己已經相信的事物找到佐證。當對氣候變化等情緒化問題持有不同信念的人們看到關於這些問題的相同資訊時,他們會更加堅持自己最初的立場。
更糟糕的是,搜尋引擎和社交媒體平臺會根據他們掌握的大量使用者過去偏好的資料提供個性化推薦。他們優先推送我們最有可能同意的資訊(無論多麼邊緣化),並將我們遮蔽在可能改變我們想法的資訊之外。這使我們很容易成為兩極分化的目標。尼爾·格林伯格和他在東北大學的同事在2019年表明,美國的保守派更容易接受錯誤資訊。但我們自己對Twitter上低質量資訊消費的分析表明,這種脆弱性適用於政治光譜的兩端,沒有人能完全避免它。即使我們檢測線上操縱的能力也受到我們的政治偏見的影響,儘管並非對稱地:共和黨使用者更可能將宣傳保守派觀點的機器人誤認為是人類,而民主黨人更可能將保守派人類使用者誤認為是機器人。
社會群體行為
2019年8月在紐約市,人們開始逃離聽起來像槍聲的聲音。其他人也跟著跑,有些人喊著“槍手!” 後來他們才知道,爆炸聲來自摩托車回火。在這種情況下,先跑為上,事後諸葛亮可能更有利。在缺乏明確訊號的情況下,我們的大腦會利用關於人群的資訊來推斷適當的行動,類似於魚群和鳥群的行為。
這種社會順從性很普遍。在2006年馬修·薩爾加尼克(當時在哥倫比亞大學)和他的同事進行的一項引人入勝的涉及14,000名網路志願者的研究中,他們發現,當人們可以看到其他人下載的音樂時,他們最終也會下載類似的歌曲。此外,當人們被隔離成“社交”群體時,他們可以看到圈子裡其他人的偏好,但對圈外人一無所知,各個群體的選擇迅速出現分歧。但是,在“非社交”群體中,沒有人知道其他人的選擇,偏好保持相對穩定。換句話說,社會群體創造了一種強大的趨同壓力,它可以克服個人偏好,並且透過放大隨機的早期差異,它可以導致隔離的群體走向極端。
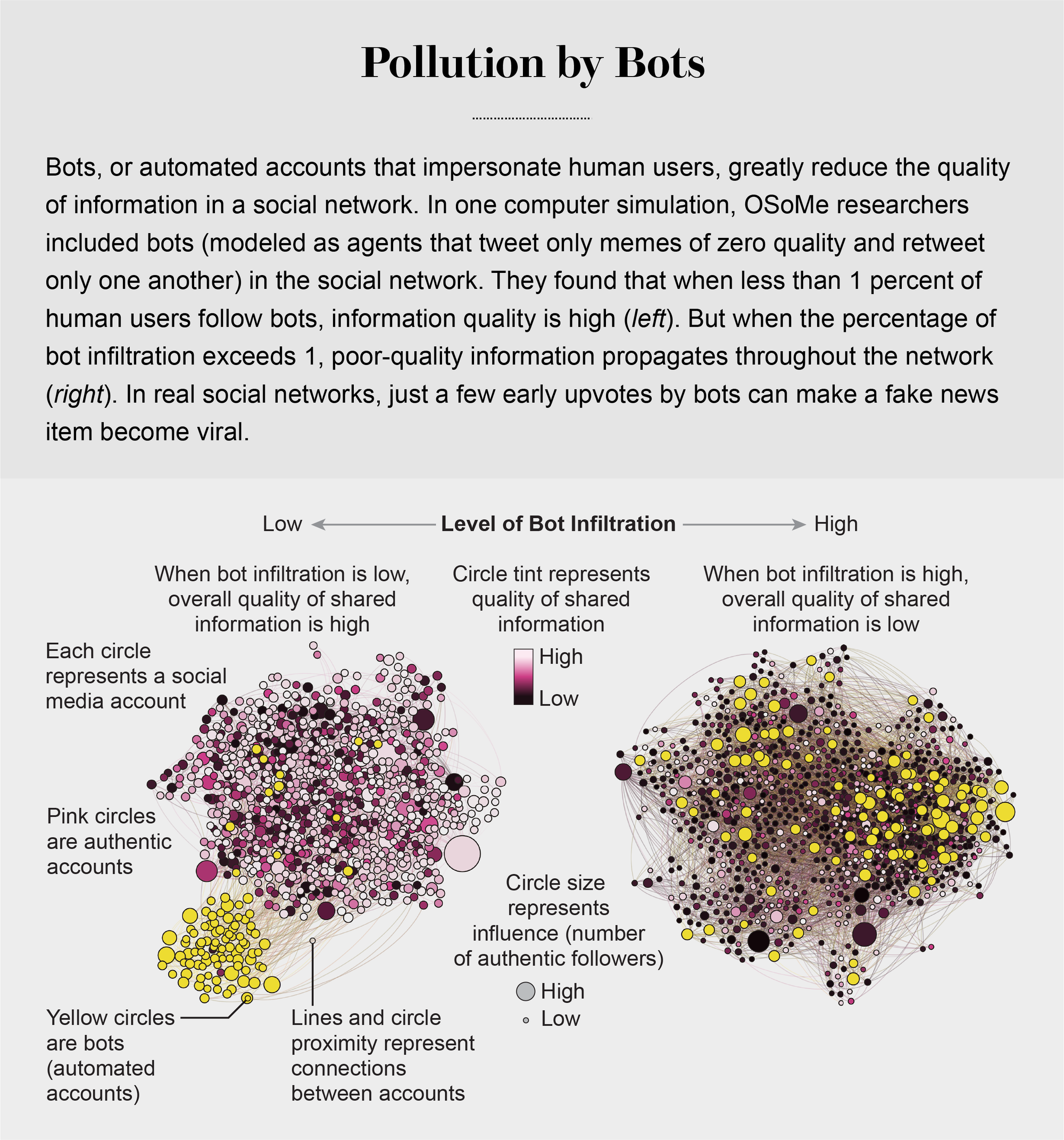
圖片來源:Filippo Menczer
社交媒體遵循類似的動態。我們將流行度與質量混淆,最終複製我們觀察到的行為。丹麥技術大學的比雅克·蒙斯特德和他的同事在Twitter上進行的實驗表明,資訊是透過“複雜傳染”傳播的:當我們反覆接觸到一個想法時,通常來自多個來源,我們就更有可能採納並轉發它。心理學家稱之為“單純曝光效應”進一步放大了這種社會偏見:當人們反覆接觸相同的刺激(例如某些面孔)時,他們會比那些他們接觸較少的刺激更喜歡這些刺激。
這些偏見轉化為一種不可抗拒的衝動,即關注正在瘋傳的資訊——如果其他所有人都在談論它,那它一定是重要的。除了向我們展示符合我們觀點的專案外,Facebook、Twitter、YouTube 和 Instagram 等社交媒體平臺還將熱門內容放在我們螢幕的頂部,並向我們展示有多少人點贊和分享了某些內容。很少有人意識到這些提示並未提供對質量的獨立評估。
事實上,為社交媒體上的迷因排名設計算法的程式設計師假設“群體智慧”將迅速識別出高質量的專案;他們使用流行度作為質量的替代指標。我們對大量關於點選次數的匿名資料的分析表明,所有平臺(社交媒體、搜尋引擎和新聞網站)都優先推送來自一小部分熱門來源的資訊。
為了理解原因,我們模擬了他們如何在排名中結合質量和流行度訊號。在這個模型中,注意力有限的代理(那些只看到新聞提要頂部給定數量的專案的人)也更可能點選平臺排名前列的迷因。每個專案都具有內在質量,以及由其被點選次數決定的流行度級別。另一個變數跟蹤排名在多大程度上依賴於流行度而不是質量。該模型的模擬表明,即使在沒有人類偏見的情況下,這種演算法偏差通常也會抑制迷因的質量。即使我們想分享最好的資訊,演算法最終也會誤導我們。
迴音室
我們大多數人都不相信自己隨波逐流。但我們的證實偏差導致我們追隨與我們相似的人,這種動態有時被稱為同質性——志同道合的人相互聯絡的傾向。社交媒體透過允許使用者透過關注、取消關注等方式改變其社交網路結構來放大同質性。結果是,人們被隔離成大型、密集且越來越被誤導的社群,通常被稱為迴音室。
在OSoMe,我們透過另一個模擬EchoDemo探索了線上迴音室的出現。在這個模型中,每個代理都有一個政治觀點,用從-1(比如,自由派)到+1(保守派)的數字表示。這些傾向反映在代理的帖子中。代理也受他們在新聞提要中看到的觀點的影響,他們可以取消關注意見不同意的使用者。從隨機的初始網路和觀點開始,我們發現社會影響和取消關注的結合大大加速了兩極分化和隔離社群的形成。
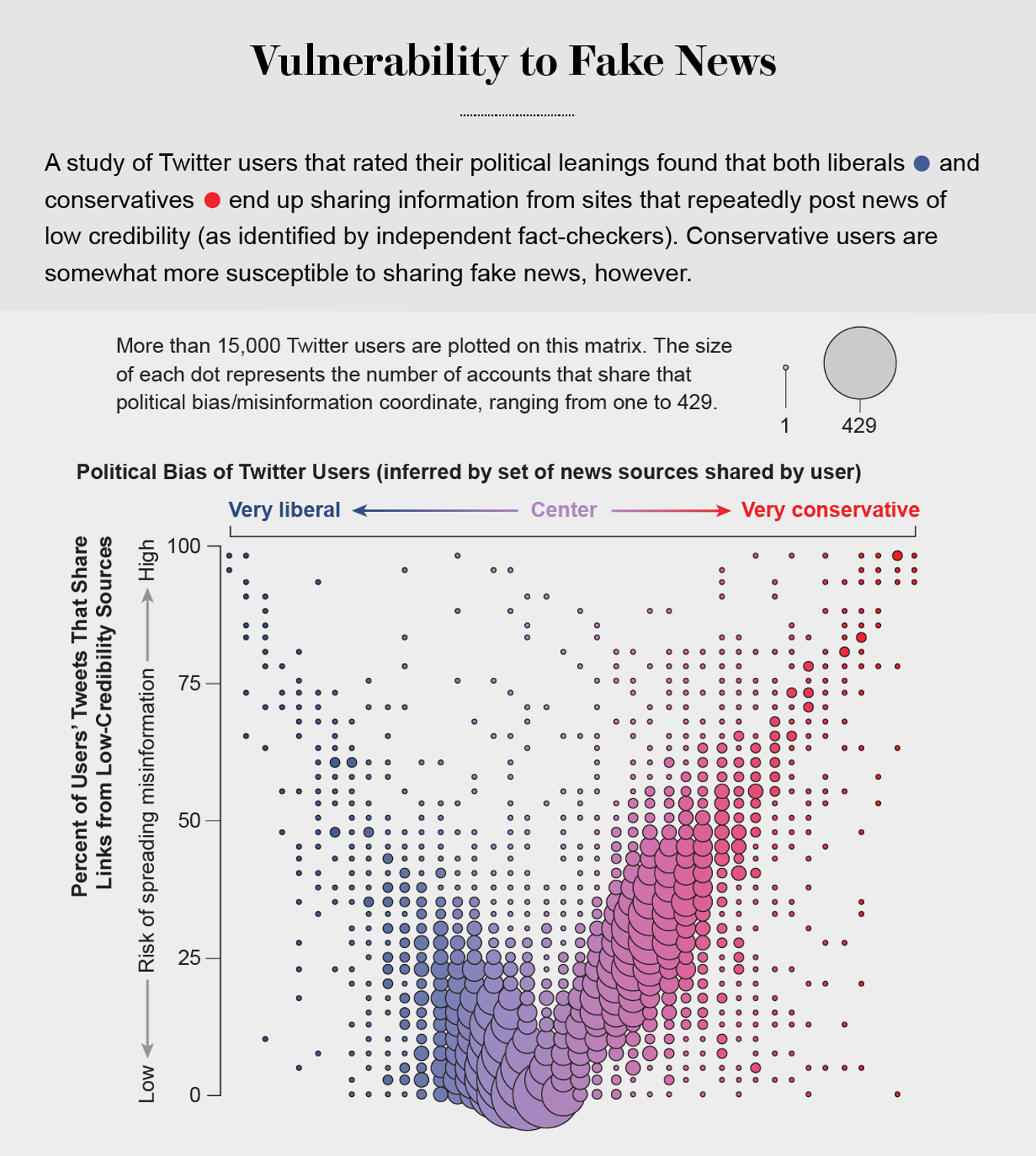
圖片來源:Jen Christiansen;資料來源:Dimitar Nikolov 和 Filippo Menczer (資料)
事實上,Twitter上的政治迴音室非常極端,以至於可以高精度預測單個使用者的政治傾向:你的觀點與你的大多數聯絡人相同。這種分室結構有效地在社群內傳播資訊,同時將該社群與其他群體隔離開來。2014年,我們的研究小組成為一場虛假資訊宣傳活動的目標,該活動聲稱我們是出於政治動機壓制言論自由的一部分。這種虛假指控主要在保守派迴音室中病毒式傳播,而事實核查員的反駁文章主要出現在自由派社群中。可悲的是,虛假新聞專案與其事實核查報告的這種隔離是常態。
社交媒體也會增加負面情緒。在2018年的一項實驗室研究中,現就職於牛津大學的羅伯特·賈吉洛和我們中的一位(希爾斯)發現,社會共享的資訊不僅會增強偏見,而且會變得更難以糾正。我們調查了資訊如何在所謂的社會擴散鏈中人與人之間傳遞。在實驗中,鏈條中的第一個人閱讀了一組關於核能或食品新增劑的文章。這些文章的設計是平衡的,包含儘可能多的正面資訊(例如,關於減少碳汙染或更持久的食物)和負面資訊(例如,熔燬風險或可能對健康造成的危害)。
社會擴散鏈中的第一個人將文章告訴下一個人,第二個人告訴第三個人,依此類推。我們觀察到,隨著負面資訊沿著鏈條傳遞,負面資訊的量總體增加——這被稱為風險的社會放大。此外,澳大利亞新南威爾士大學的丹妮爾·J·納瓦羅和她的同事的工作發現,社會擴散鏈中的資訊最容易被偏見最極端的人扭曲。
更糟糕的是,社會擴散也使負面資訊更“粘性”。當賈吉洛和希爾斯隨後讓社會擴散鏈中的人們接觸到原始的平衡資訊時——即鏈條中的第一個人看到的新聞——平衡資訊對減少個人的負面態度幾乎沒有作用。透過人際傳播的資訊不僅變得更加負面,而且更難以更新。
艾米利奧·費拉拉和澤堯·楊(當時都是OSoMe的研究人員)在2015年的一項研究中分析了關於Twitter上這種“情緒傳染”的經驗資料,發現過度接觸負面內容的人傾向於分享負面帖子,而過度接觸正面內容的人傾向於分享更多正面帖子。由於負面內容比正面內容傳播得更快,因此很容易透過建立引發恐懼和焦慮等負面反應的敘事來操縱情緒。費拉拉(現就職於南加州大學)和他在義大利布魯諾·克 Kessler基金會的同事已經表明,在西班牙2017年關於加泰羅尼亞獨立的公投期間,社交機器人被用來轉發暴力和煽動性敘事,增加了它們的曝光率並加劇了社會衝突。
機器人的崛起
社交機器人進一步損害了資訊質量,社交機器人可以利用我們所有的認知漏洞。機器人很容易建立。社交媒體平臺提供所謂的應用程式程式設計介面,這使得單個行為者可以非常輕鬆地設定和控制數千個機器人。但是,放大一條訊息,即使只是在Reddit等社交媒體平臺上獲得機器人的一些早期贊成票,也可能對帖子隨後的受歡迎程度產生巨大影響。
在OSoMe,我們開發了機器學習演算法來檢測社交機器人。其中之一是Botometer,這是一個公共工具,它從給定的Twitter帳戶中提取1,200個特徵,以描述其個人資料、朋友、社交網路結構、時間活動模式、語言和其他特徵。該程式將這些特徵與先前識別的數萬個機器人的特徵進行比較,從而為Twitter帳戶的自動化使用可能性評分。
2017年,我們估計,高達15%的活躍Twitter帳戶是機器人——並且它們在2016年美國大選期間的錯誤資訊傳播中發揮了關鍵作用。在虛假新聞文章釋出後的幾秒鐘內——例如一篇聲稱克林頓競選團隊參與了神秘儀式的文章——許多機器人就會在Twitter上釋出該文章,而受內容表面上的受歡迎程度所迷惑的人類會轉發它。
機器人還透過假裝代表我們群體內部的人來影響我們。一個機器人只需要關注、點贊和轉發線上社群中的某個人,就可以迅速滲透到該社群中。北京師範大學的樓曉丹與OSoMe合作開發了另一個模型,其中一些代理是機器人,它們滲透到社交網路中並分享具有欺騙性的低質量內容——想想點選誘餌。模型中的一個引數描述了真實代理關注機器人的機率——為了這個模型的目的,我們將機器人定義為生成零質量迷因並且只相互轉發的代理。我們的模擬表明,這些機器人只需滲透到網路的一小部分,就可以有效地抑制整個生態系統的資訊質量。機器人還可以透過建議關注其他不真實的帳戶來加速回音室的形成,這種技術被稱為建立“關注列車”。
一些操縱者透過獨立的虛假新聞網站和機器人來玩弄分裂的兩面,從而推動政治兩極分化或透過廣告獲利。在OSoMe,我們發現了一個Twitter上的不真實帳戶網路,這些帳戶都由同一個實體協調。有些假裝是特朗普“讓美國再次偉大”美國總統競選活動的支持者,而另一些則冒充特朗普“抵抗者”,他們都要求政治捐款。此類行動放大了利用證實偏見的內容,並加速了兩極分化的迴音室的形成。
遏制線上操縱
瞭解我們的認知偏差以及演算法和機器人如何利用它們,使我們能夠更好地防範操縱。OSoMe製作了許多工具,以幫助人們瞭解自己的弱點以及社交媒體平臺的弱點。其中一個是名為Fakey的移動應用程式,它可以幫助使用者學習如何識別錯誤資訊。該遊戲模擬社交媒體新聞提要,顯示來自低可信度和高可信度來源的真實文章。使用者必須決定他們可以或不應該分享什麼,以及要對什麼進行事實核查。來自Fakey的資料分析證實了線上社會群體行為的普遍性:當用戶認為許多其他人分享了低可信度的文章時,他們更有可能分享這些文章。
另一個可供公眾使用的程式名為Hoaxy,它顯示了任何現有的迷因如何在Twitter上傳播。在這個視覺化中,節點代表真實的Twitter帳戶,連結描述了轉發、引用、提及和回覆如何將迷因從一個帳戶傳播到另一個帳戶。每個節點都有一個顏色,代表其來自Botometer的分數,這使使用者可以看到機器人放大錯誤資訊的規模。調查記者已經使用這些工具來揭露錯誤資訊宣傳活動的根源,例如在美國推動“披薩門”陰謀論的宣傳活動。它們還有助於檢測2018年美國中期選舉期間機器人驅動的選民壓制行動。然而,操縱正變得越來越難以發現,因為機器學習演算法在模仿人類行為方面變得越來越出色。
除了傳播虛假新聞外,錯誤資訊宣傳活動還可以轉移人們對其他更嚴重問題的注意力。為了打擊這種操縱,我們開發了一種名為BotSlayer的軟體工具。它提取使用者希望研究的主題的推文中共現的主題標籤、連結、帳戶和其他特徵。對於每個實體,BotSlayer會跟蹤推文、釋出推文的帳戶及其機器人評分,以標記正在趨勢化並且可能被機器人或協同帳戶放大的實體。目標是使記者、公民社會組織和政治候選人能夠即時發現和跟蹤不真實的影響力宣傳活動。
這些程式化工具是重要的輔助工具,但制度變革對於遏制虛假新聞的擴散也是必要的。教育可以提供幫助,儘管它不太可能涵蓋人們被誤導的所有主題。一些政府和社交媒體平臺也在嘗試打擊線上操縱和虛假新聞。但是,誰來決定什麼是虛假的或具有操縱性的,什麼不是?資訊可以附帶警告標籤,例如Facebook和Twitter提供的標籤,但是應用這些標籤的人可以信任嗎?這種措施可能有意或無意地壓制對健全的民主至關重要的言論自由的風險是真實存在的。在全球範圍內具有影響力的社交媒體平臺以及與政府的密切聯絡進一步使可能性複雜化。
最好的想法之一可能是使建立和共享低質量資訊更加困難。這可能涉及透過迫使人們付費共享或接收資訊來增加摩擦。付款可以是時間、腦力勞動(如謎題)或訂閱或使用費的形式。自動化釋出應像廣告一樣對待。一些平臺已經在使用摩擦,形式為CAPTCHA和電話確認來訪問帳戶。Twitter已對自動化釋出施加了限制。可以擴大這些努力,以逐步將線上共享激勵轉向對消費者有價值的資訊。
自由溝通並非免費。透過降低資訊的成本,我們降低了資訊的價值,並招致了資訊的摻假。為了恢復我們資訊生態系統的健康,我們必須瞭解我們不堪重負的大腦的脆弱性,以及如何利用資訊經濟學來保護我們免受誤導。